This week we see how TwitterTrails evaluates the credibility of a rumor spreading in social media, and we learn how new tools are making it easier to extract data from websites.
PART 1: TwitterTrails
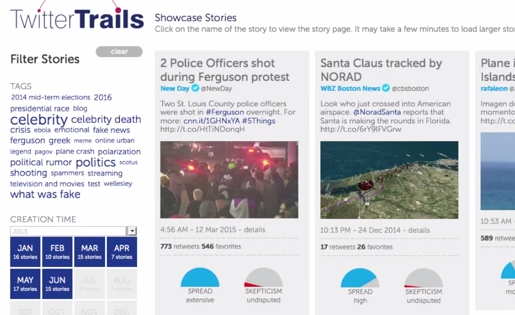
Developed as part of a research project at Wellesley College, TwitterTrails can trace the origins of rumors on Twitter to see how far they’ve spread and gauge the corresponding level of skepticism. We get an overview of how it works from Takis Metaxas, a director of the project, who says the tool ultimately can help journalists determine if a rumor is true or false.
Reporting by Daniel Shapiro.
[To skip directly to this segment in YouTube, click here.]
For more information:
Journalists can request an account by emailing Takis Metaxas at [email protected]. Members of the public can also submit ideas to be investigated via the TwitterTrails website.
Metaxas provides a more in-depth demonstration and explanation in this video prepared for the Journalism/Interactive conference held in April
The TwitterTrails blog provides case study examples related to specific news events, such as the Ferguson protests.
PART 2: Web scraping tools
Several apps and browser plug-ins now enable journalists to quickly extract batches of information from Web pages without learning how to code. We get an introduction to what the tools can do from Michelle Minkoff, data journalist at the Associated Press.
Reporting by Berkeley Lovelace and Katy Mersmann.
[To skip directly to this segment in YouTube, click here.]
A few Web scraping tools:
- OutWit Hub – A tool that enables users without programming skills to extract links, images, email addresses, and other information. Data can be saved into CSV, HTML, Excel, or SQL databases, while images and documents are saved directly to a hard disk. Free version has a limit on the amount of data that can be extracted.
- Import.io – A simple online tool where users can enter a Web page’s URL and download the extracted results as a spreadsheet file. There’s also a desktop app that can crawl entire websites. In addition, the company offers a more advanced enterprise option.
- DownThemAll – A free plug-in for Firefox browser that enables users to download links, images and/or text from a Web page.
- Kimono – Extractor tool that, without requiring a user to write code, turns material from Web pages into API data feeds for use by other websites, mobile apps, etc. Available for free. A paid enterprise-level plan includes more advanced service and support.
- Scraper – A “simple (but limited) data mining extension” that works with Google’s Chrome browser.
- Web Scraper – A free Chrome browser extension that follows a site map adjusted by the user to extract information from multiple related Web pages. The company also offers an enterprise-level data extraction service.
For more information:
A helpful guide, compiled by Samantha Sunne and Matt Wynn for the 2015 IRE conference, provides several options and instructions for pulling information from websites.
Reuben Stern is the deputy director of the Futures Lab at the Reynolds Journalism Institute and host and co-producer of the weekly Futures Lab video update.
 The Reynolds Journalism Institute’s Futures Lab video update features a roundup of fresh ideas, techniques and developments to help spark innovation and change in newsrooms across all media platforms. Visit the RJI website for the full archive of Futures Lab videos, or download the iPad appto watch the show wherever you go. You can also sign up to receive email notification of each new episode.
The Reynolds Journalism Institute’s Futures Lab video update features a roundup of fresh ideas, techniques and developments to help spark innovation and change in newsrooms across all media platforms. Visit the RJI website for the full archive of Futures Lab videos, or download the iPad appto watch the show wherever you go. You can also sign up to receive email notification of each new episode.
